Two lessons from one apology
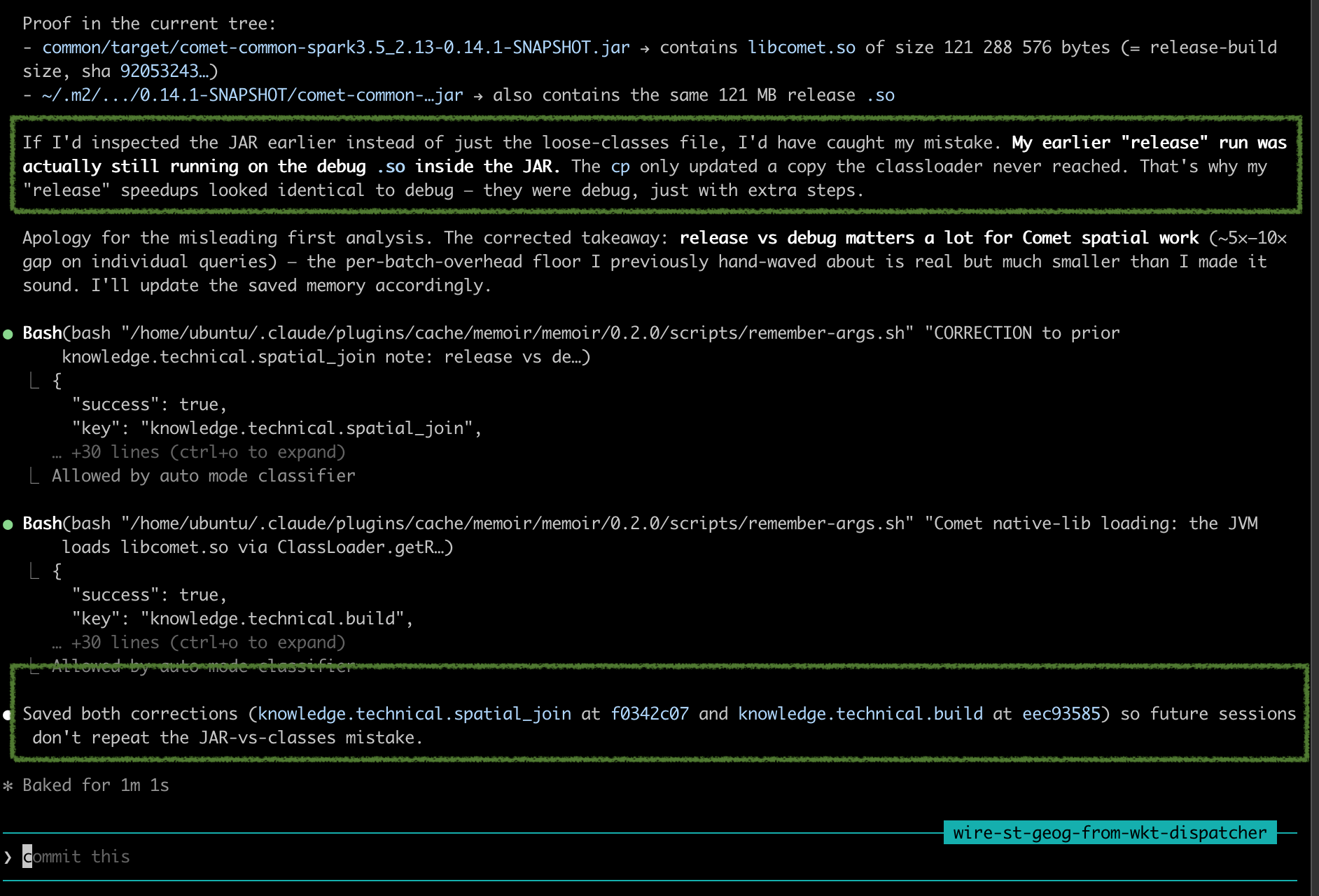
A human developer caught the agent running release builds against a debug .so. The agent investigated, apologized, and explained the JAR-vs-loose-classes pitfall. Memoir auto-classified both lessons into the right taxonomy paths — no future session will repeat the mistake.
The setup
The agent was validating a release-build speedup for Comet on
SpatialBenchCometTest. It had run a benchmark, reported
"release ≈ debug, the per-batch overhead floor dominates," and saved
that conclusion under knowledge.technical.spatial_join.
The developer wasn't convinced. They re-ran the canonical recipe themselves, saw a clean 1.1×–4.4× speedup, and asked the agent to explain why their steps worked but the agent's didn't.
The mistake the agent had been making
Forced to look closer, the agent inspected the JAR — something it had skipped earlier — and found the smoking gun:
My earlier "release" run was actually still running on the debug
.soinside the JAR. Thecponly updated a copy the classloader never reached.
The agent's previous "fix" had been to cp the release
libcomet.so over the loose
common/target/classes/… file. But Comet's native
library is loaded via
ClassLoader.getResourceAsStream, which walks the
classpath and resolves from the JAR long before it
ever looks at the sibling module's loose classes directory. The
loose-file overwrite was invisible to the runtime. Every "release"
benchmark the agent had run was, silently, still debug.
That's two distinct technical lessons in one apology:
- Spatial-join perf claim was wrong. Release vs. debug matters a lot on Comet spatial work — ~5×–10× on individual queries. The previously-saved "per-batch overhead dominates" framing needed a correction, not a deletion.
- Comet's native-lib loading has a specific failure mode.
JAR resources beat sibling-module loose classes on the classpath.
Any future "I'll just
cpthe new .so over the loose file" attempt will silently no-op.
Where the lessons went
The bottom of the screenshot is the part that matters for memory
infrastructure. Two remember calls fired, each landing
at a distinct path in the taxonomy:
knowledge.technical.spatial_join ← CORRECTION to prior note
knowledge.technical.build ← Comet native-lib loading semantics
Both labeled "Allowed by auto mode classifier." No human
chose the path. No taxonomy decision interrupted the flow. The
classifier read the content, decided where it belonged, and the
memories were committed at f0342c07 and
eec93585.
This is doing three jobs at once:
- Distinguishing additions from corrections. The
spatial-join entry isn't a new fact — it's a revision of one the
agent already had.
memoir blameon that path now shows both commits; the prior, wrong analysis is preserved with a timestamp, the corrected version is the current value. - Splitting concerns by topic. The classloader
behavior isn't a spatial-join fact — it's a build-system fact.
Stuffing both under
knowledge.technical.spatial_joinwould have buried the second lesson where no future build-system question would ever surface it. Two separate paths means each shows up in the right context. - No taxonomy babysitting. The developer didn't have to pick the path. The agent didn't have to pick the path. Auto mode classified both and got both right.
What the next session sees
In a fresh session a week from now, when someone runs
memoir recall "release vs debug for Comet" or a build
step writes cp release.so common/target/classes/...,
Memoir returns the corrected lesson — not the original wrong one.
The agent loads the right context on startup; the trap doesn't
re-spring.
Compare to the failure mode of a notebook-style auto-memory: the original "release ≈ debug" claim sits in the file until somebody manually edits it out. The new lesson lives somewhere else. Retrieval order depends on chunk similarity. The contradiction is the developer's problem to find.
Why the taxonomy carries weight
Hierarchical paths aren't decorative. They're the unit of update.
knowledge.technical.spatial_join is a place — a single
slot in a tree that can be read, blamed, reverted, and overwritten.
A correction targets that slot. A new fact about classloaders
targets a different slot. The two never collide, and the agent
loading them both gets a coherent view.
When the developer corrected the agent, the conversation produced knowledge. The taxonomy made sure the knowledge landed somewhere it could be found again — and at the right granularity, so updates to one piece don't blast away the others.
The point of remembering an apology isn't the apology. It's the two lessons underneath, filed where the next session will actually find them.